Redis补充
1 Redis网络模型
Redis的核心业务部分(命令处理)是单线程,但是整个Redis是多线程的。
- v4.0:引入多线程异步处理一些耗时较长的任务,例如异步删除命令unlink。
- v6.0:在核心网络模型中引入多线程,进一步提高对于多核CPU的利用率,但是核心部分依然是单线程。
为什么选择单线程?
- 性能瓶颈是网络延迟,不是执行速度,多线程并不会带来巨大性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销。
- 引入多线程可能会面临线程安全问题,必须引入线程锁这样的安全手段,实现复杂度增高,性能也大打折扣。
原理篇-27.Redis网络模型-Redis单线程及多线程网络模型变更_哔哩哔哩_bilibili
2 Redis通信协议
RESP协议
原理篇-28.Redis通信协议-RESP协议_哔哩哔哩_bilibili
3 Redis事务
Redis事务的三个阶段
MULTI %事务开始
... %命令入队
EXEC %事务执行
Redis事务特点
- redis不支持回滚,事务失败,继续执行余下的命令
- 事物内部命令错误,所有命令都不会执行
- 事物内部出现运行错误,正确的命令会被执行
- Redis事务没有原子性,持久性仅在开启AOF的always模式下支持。
- Redis事务总是有隔离性(单线程)和一致性。
Redis事务相关命令
- WATCH:乐观锁,给事务提供CAS机制,可以监控一个或者多个键,一旦其中有一个被修改,之后的事务就不会执行,监控一直持续到EXEC或者UNWATCH。
- MULTI:用于开启事务,开启后可以继续送入命令,当EXEC被调用时,才被执行。
- EXEC:执行事务块内所有命令,返回所有命令的返回值,按照命令先后排序。
- DISCARD:清空事务队列,放弃执行事务。
- UNWATCH:取消watch对所有key的监控。
4 缓存和数据库的一致性
- 设置有效期:给缓存设置有效期,到期自动删除,再次查询时更新
- 优势:简单方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求较低的业务
- 同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高
- 场景:对一致性,时效性要求较高的缓存数据
- 异步通知:在修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
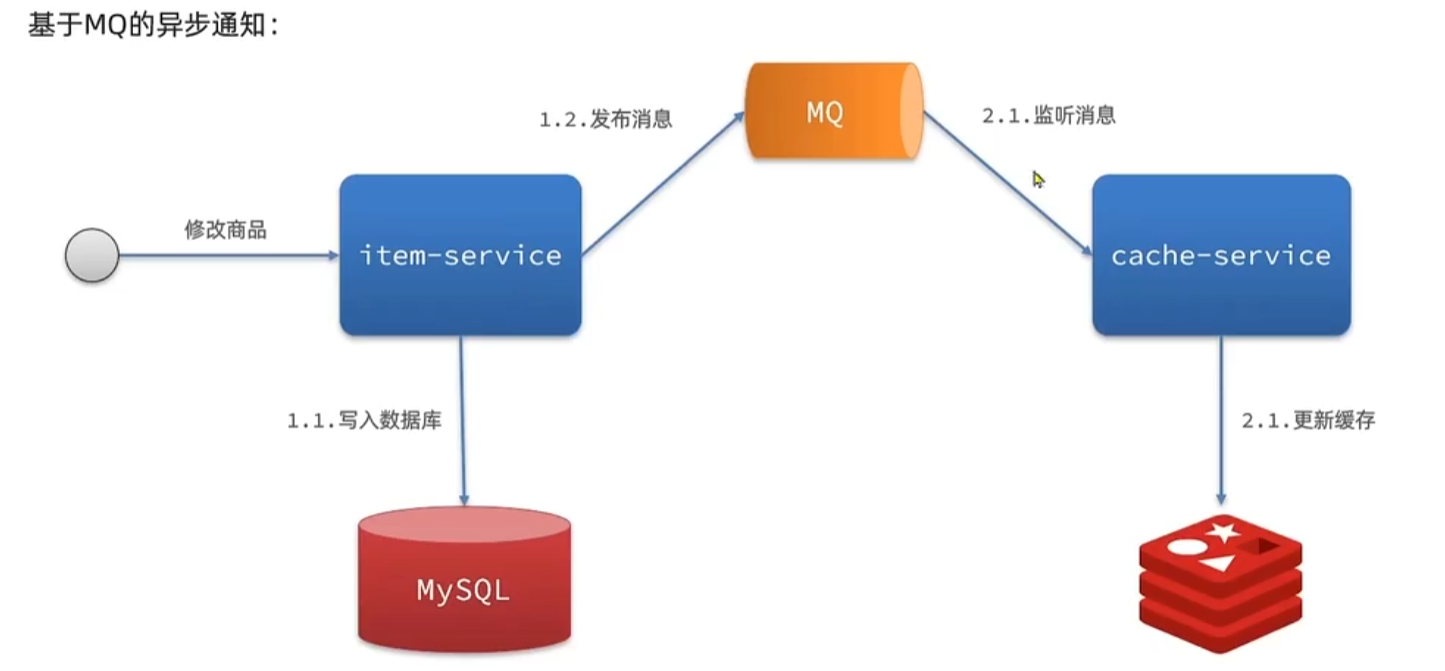
- 基于MQ的异步通知,对业务代码仍然有一定侵入性
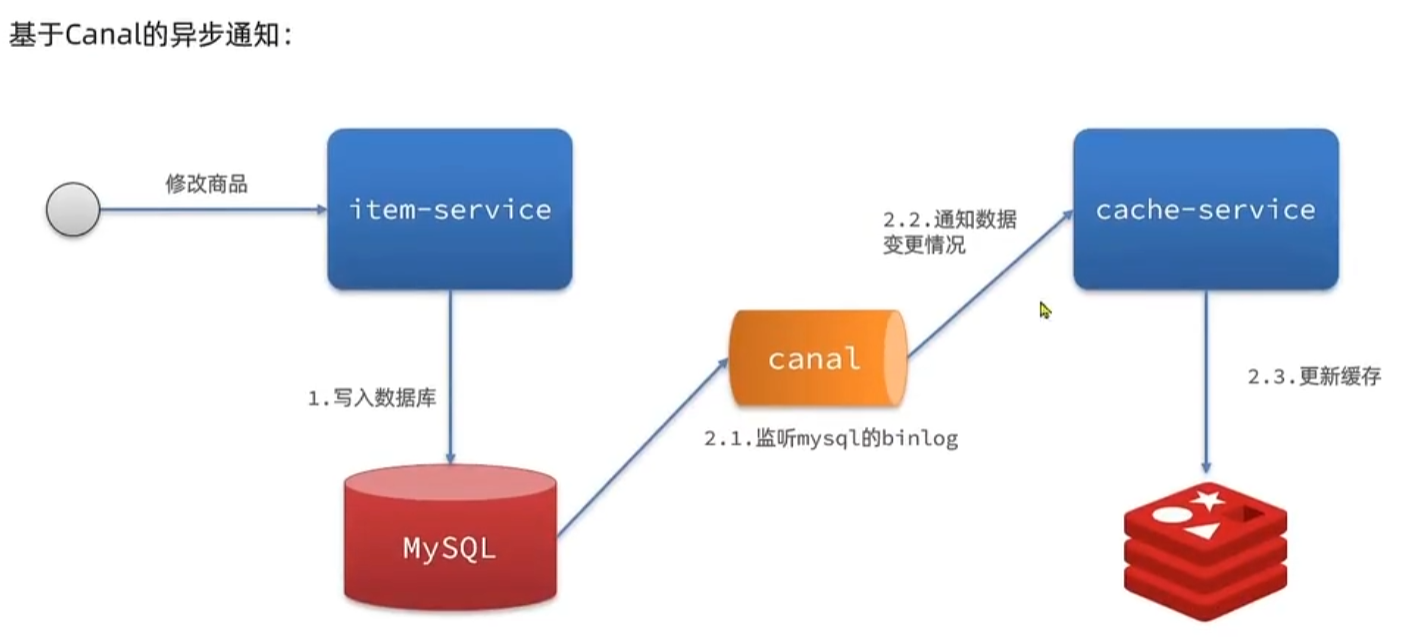
- 基于Cannal的异步通知,可以做到几乎0侵入
4.1 缓存更新策略
- 删除缓存而不是更新缓存
- 先删数据,后删缓存
4.2 缓存不一致处理
- 使用消息队列,把要删除和删除失败的key放入消息队列,利用重试机制,删除对应的key
- 对代码有侵入性
- 数据库订阅+消息队列保证key被删除
- 利用canal或其他服务监听binlog
- 复杂度提升
- 延时双删防止脏数据
- 延迟时间需要具体的考量和测试
- 设置过期时间兜底
5 热key重建
- 使用互斥锁,保证只有一个线程重建,其他线程等待该线程重建完后,获取缓存数据即可。
- 不显示设置过期时间,而是设置逻辑过期字段,发现逻辑过期后,采用单独的线程构建缓存。
6 大key问题
单个简单key存储的value过大,hash、set、zset、list中存储过多元素。
大Key会造成什么问题?
- 客户端耗时增加
- 对大key进行IO操作时,会严重占用带宽和CPU
- 造成Redis集群中的数据倾斜
- 主动删除、被动删除,可能会导致阻塞。
如何找到大Key?
- bigkeys命令:以遍历方式分析Redis实例中所有key,并返回整体统计信息和每个数据类型中top1的大key。
- redis-rdb-tools:是由Python写的用来分析Redis的rdb快照文件的工具,可以把rdb文件生成json文件或报表来分析Redis的使用详情。
如何处理大Key?
- 删除大Key
- unlink非阻塞删除
- 压缩和拆分大Key
- string优先进行压缩,然后进行拆分
- list、set等,进行分片
7 Redis实践
7.1 基于Redis的消息队列
Redis提供了三种不同方式实现消息队列:
- list结构:模拟消息队列
- PubSub:基本的点对点消息模型
- Stream:比较完善的消息队列模型
List模拟消息队列
利用LPUSH结合RPOP、或者RPUSH结合LPOP来实现。

当没有消息时,RPOP和LPOP命令会返回NULL,并不会像JVM阻塞队列那样阻塞并等待消息。所以应当使用BRPOP或者BLPOP来实现阻塞效果。
- 利用Redis存储,不受JVM内存上限限制
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息的有序性
- 无法避免消息丢失
- 只支持单消费者
PubSub消息队列
消费者可以订阅一个或者多个channel,生产者向对应的channel发送消息后,所有订阅者都能收到相关消息。
- SUBSCRIBE channel [channel]:订阅一个或多个频道
- PUBLISH channel msg:向一个频道发送消息
- PSUBSCRIBE pattern [pattern]:订阅与pattern格式匹配的所有频道
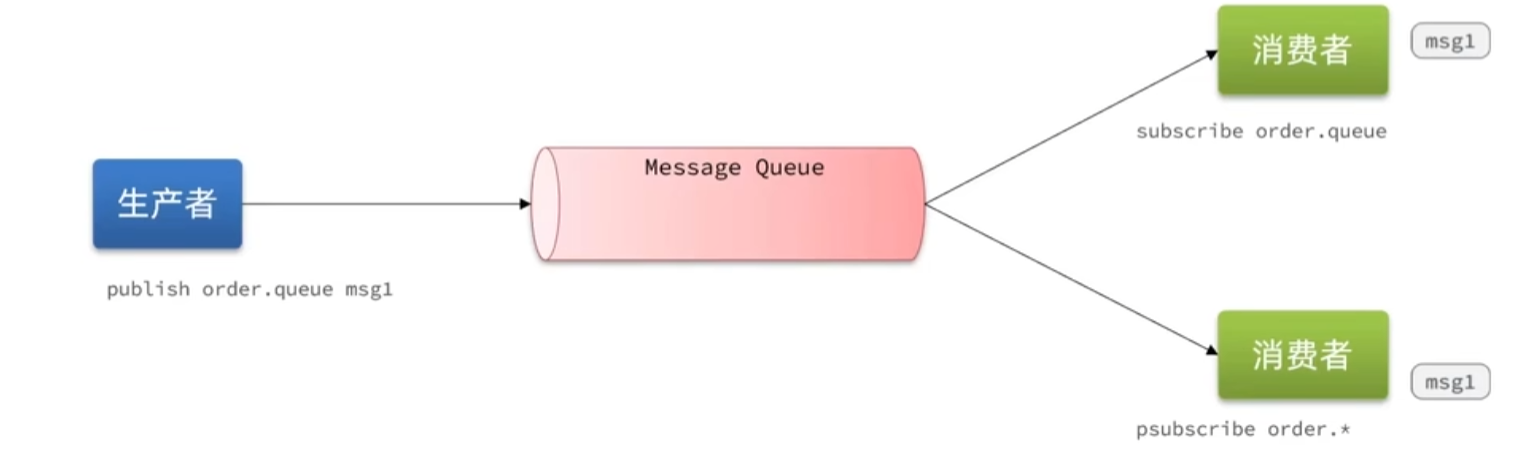
- 采用发布订阅模型,支持多生产、多消费。
- 不支持数据持久化,该数据结构设计用于做数据发送,数据没有人接受会直接丢弃。
- 无法避免消息丢失。
- 消费者方消息堆积有上线,超出时数据丢失。
Stream消息队列
- XREAD
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
- 消费者组
- 消息分流
- 消息标识
- 消息确认
- 可以多消费者争抢消息,加快消费速度
- 没有消息漏读风险
- 有消息确认机制,保证消息至少被消费一次
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加速处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |